1. 层次聚类两种基本方法:凝聚的和分裂的
- 凝聚的:从点作为个体簇开始,每一步合并两个最接近的簇。这里需要定义簇的邻近性概念,如图所示。
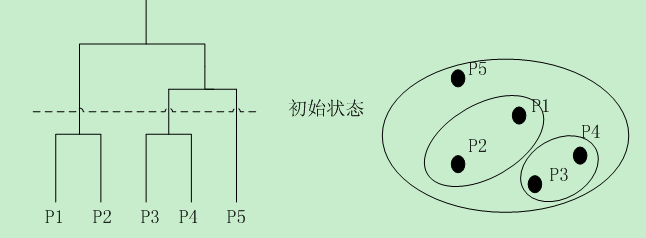
- 分裂的:从包含所有点的某个簇开始,每一步分裂一个簇,直到仅剩下单个点簇。这种情况比较复杂,我们需要确定每一步分裂哪个簇,以及如何分裂。

2. 常用的基于凝聚的层次聚类
下面探讨两个问题:
1) 定义簇之间的邻近性(需要注意的是两个点的距离可以根据自己的需要去定义,这里说的是如何根据簇内多个点与其他点或者簇计算两个簇之间的邻近性)
源于簇的基于图的术语,有MIN、MAX、和组平均三种方法。MIN定义簇之间的邻近度为不同簇的两个最近的点之间的邻近度(图的术语表示:不同的结点子集中两个结点之间的最短边)。MAX取不同簇中两个最远的点之间的邻近度。通常我们使用单链(single link)和全链(complete link)来分别表示这两种方法。组平均定义簇邻近度为取不同簇的所用点对邻近度的平均值(平均变长)。三种方法如图所示。
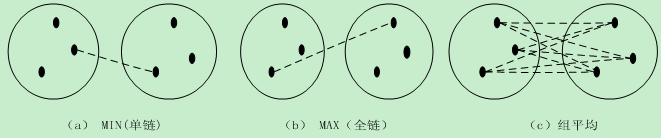
当然,簇也可用质心代表,这样邻近度的定义为质心之间的距离就更加自然。还有一种方法Ward,该方法试图最小化点到其簇质心的距离的平方和。
2) 时间和空间复杂性
需要存储m2/2个邻近度,其中m是数据点的个数。因此空间复杂度为O(m2)。
需要O(m2)时间计算邻近度矩阵,之后步骤3和4涉及m-1次迭代,如果某个簇到其他所有簇的距离存放在一个有序表或堆中,则查找两个最近簇的开销可能为O(m-i+1).总时间为O(m2logm)。
3. 问题及优缺点
层次聚类的主要问题主要包括
1) 缺乏全局目标函数,使用各种标准在每一步局部地确定哪些簇应当合并,成功避开了解决困难的组合优化问题。但是这样的方法没有局部极小问题或很难选择初始点。
2) 处理不同大小簇的能力,若想平等地对待不同大小的簇,必须赋予不同簇中的点不同的权值。
3) 合并决策是不可逆的,一旦做出决策,就不能撤销了。
优点与缺点:
比较适合那些需要层次结构的应用,通常情况下,层次聚类会产生较高质量的聚类结果并可以根据邻近度阈值等相关指标确定聚类个数。然而计算量和存储代价是昂贵的,高维数据可能会出现较大问题。由于是不可逆的,对于噪声比较敏感。有些研究先使用其他聚类算法进行部分聚类,然后利用之前聚好的簇再进行层次聚类往往可以解决上述问题。
张晗
2015.1.28
原创文章,作者:admin,如若转载,请注明出处:https://www.isclab.org.cn/2015/01/28/%e5%b1%82%e6%ac%a1%e8%81%9a%e7%b1%bb%e7%ae%97%e6%b3%95/
