背景
熟悉模式识别的童鞋都很清楚,在模式识别领域内存在许多的学习算法和技术。面对纷繁的算法,我们必然会产生疑问:究竟哪一个算法才是“最好的”。值的强调的是每个算法都有相应的先验假设,针对某个问题看上去比另一个算法好,也仅仅说明该算法更是这这一特定的模式识别任务。总而言之就是没有天生优越的算法。
实际中,我们通常会偏爱一些算法,大多因为他们有相对较小的计算复杂度。这也就是说,如果有两个分类器在训练集上有同样的性能,一般会认为较简单的一个在测试集上能得到更好的效果。也就是说它的泛化能力更好。这个结论是否正确、合理呢?本文将针对这个问题展开讨论。
如果对问题的类别概率不作任何限制,那么是没有普适的最优分类器。因此对于任何给定的问题,我们必须做好充分的准备去探索大量的方法或者模型。为了便于衡量学习算法的效果,有偏差和方差两个度量分别表征学习算法与给定分类问题的“匹配”和“校准” 程度。
基本概念
首先来学习两个统计学概念:偏差和方差。偏差描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据;方差描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。举例来说,假设有4个运动员参加的射击决赛,不通过精确的计算所得环数,而仅仅通过直接的观察怎么确定选手的排名的问题。其中4名选手的射击靶标结果如下图所示。
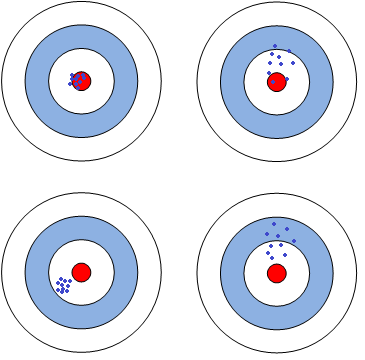

容易看出,成绩最好的肯定是左上角射击结果的运动员,因为他的射击目标大多在靶心附近,而且相对稳定。成绩最差的肯定是右下角射击结果的选手,他的射击目标大多偏离中心较远,而分布范围较大,不够稳定。而右上和左下两名选手的成绩确较难判定,前者有出现离中心较近的射击,但也有较处于蓝色环区的射击,不够稳定;而后者所有射击结果均处于离中心最近的那一环区,相对稳定。这直观观察不到两者总得分的情况,所以不好判断。同时假设两者得分恰好相同,如何又当如何比较呢。这就是一个折中的问题了,而且就遇到了取舍选择了。在此,我将从两个角度分析右上和左下两名选手的结果。
-
1. 从教练参加大赛代表角度看,这两名选手得分一样,但是左下选手成绩较为稳定,以较为稳定的心理素质顶住了比赛的压力,稳定发挥着自己的真实水平,这在大赛中不会有大的起伏,必然值的信任。
- 2. 从教练选才的角度看,相同成绩的结果,但是右上选手可以打出中心成绩,说明有较高的潜力可以开发;而与此同时左下选手则较为平庸,虽然心理素质稳定,也恰恰说明该选手的极限能力就在于此了,难以开发。所以,右上选手更值得培养。
在上例,射击结果离中心的偏差和自身之间的差别分别对应了偏差和方差。而分析中正好映射了生活中我们常常遇到的偏差和方差折中问题。
在医学标准领域,专门用来评价标准的指标为:信度和效度。信度指测验结果的一致性、稳定性及可靠性,一般多以内部一致性来加以表示该测验信度的高低;效度是指测量工具或手段能够准确测出所需测量的事物的程度。以生活中常见的测试试卷为例,这份试卷的效度就是试卷的结果可以多大程度上衡量受试者的学习效果。而信度就是指在假设受试者学习效果不变的情况下,在不同测试环境、时间下的多次测试结果较为相近。仔细分析,效度用以表征测试结果与受试者学习效果的偏差;而信度则是测试结果之间的方差。由此可以看出,信度和方差、效度和偏差衡量相同的目标,用于不同领域的名词。信度和效度最早出现于心理医学的测试量表的评价中,后来被逐步推广到医学判定标准的评价中。在此为了说明两者的关系,接下来的分析将以偏差和方差作为分析目标,不在涉及信度和效度。
在模式识别领域,以分析目标的情况可以划分为三大类:回归、分类、聚类。回归问题的目标变量式连续的,目标是准确的预测样本的可能目标值;分类问题的目标变量式离散的,目标是精确匹配样本最可能的归属类别;聚类问题目标变量也是离散的,目标是较为模糊的说明样本之间可能会被划分到哪一簇中,而这些簇之间没有明显的类别对应关系。其中回归和分类过程中需要数据的标签信息,因此称之为有监督学习;而聚类过程不需要标签信息,为此称之为无监督学习。而偏差是指预测值和实际值之间的偏差,明显是针对监督学习的。接下来的分析主要针对监督学习。
偏差方差分解
分类问题结果虽然是离散的,但是在过程中主要是对概率的回归,最后通过概率值进行类别指派,所以分类问题的评价可以借助回归问题的指标来开展。为此对偏差和方差的分析可以以回归问题为例进行分析。而回归问题追求的目标就是预测值和标签信息之间最为接近。回归的问题的评价指标——均方误差,其计算方法如下式
$$MSE=\frac{1}{m}\sum_{i=1}^{m}(y_i-\hat h(x_i))^2=E[(y-\hat h(x))^2]$$
式中,\( y \)对应专家标注,理解为\( y(x) \)而\( \hat h(x_i) \)对应为一次训练的模型。接下来对MSE进行分解。
\( \begin{equation}
\begin{split}
E[(y-\hat h(x))^2] & = E[y^2+\hat h(x)^2-2y*\hat h(x)] \\
& = E[y^2]+E[\hat h(x)^2]-2E[y*\hat h(x)] \\
& = Var[y]+E[y^2]+Var[\hat h(x)]+(E[\hat h(x)])^2-2*E[\hat h(x)]E[y] \\
& = Var[y]+Var[\hat h(x)]+(h(x)-E[\hat h(x)])^2 \\
& = sigma^2+Var[\hat h(x)]+Bias(\hat h(x))
\end{split}
\end{equation}
\)
推导过程中涉及三个关键关系:
$$Var[y]=E[y^2]-E[y]^2 导出 E[y^2]=Var[y]+E[y]^2 $$
$$ y=h(x)+\epsilon 导出 E[y]=E[h(x)+\epsilon]=E[h(x)]+E[\epsilon]=h(x) $$
$$ Var[y]=E[(y-E[y])^2]=E[(y-(y-\epsilon))^2]=E[\epsilon^2]=Var[\epsilon]+E[\epsilon]=\sigma^2 $$
从均方误差的分解结果来看,最终划分为三部分。
- 1. \( \sigma^2 \)是数据的固有噪声,与模型训练系统无关,无法改变。
- 2. \( Var[\hat h(x)] \)是训练模型的方差,为了最小化MES,也就要求模型稳定,实质就是多次训练变化较小。
- 3. \( Bias(\hat h(x)) \)是训练模型的偏差,为了最小化MSE,就要求模型最大限度的拟合真实函数。
实验分析
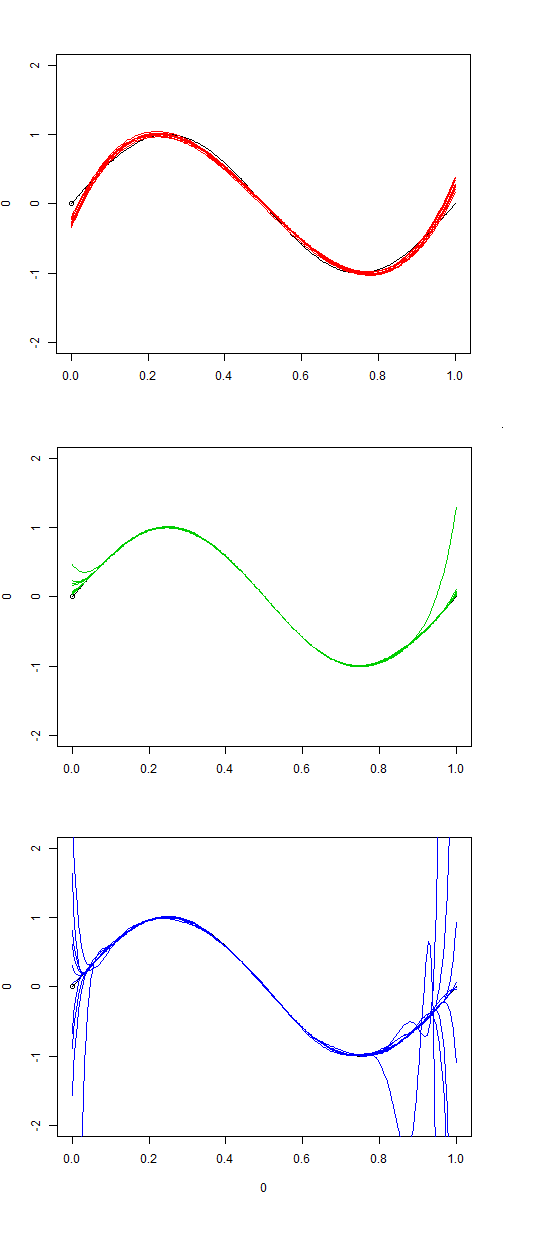
模型训练的目标就是要最小化均方误差,而通过以上分析已经将均方误差划分为可调的偏差和方差两个部分。为了分析偏差和方差的折中。设计实验证明,实验中中通过改变训练数据集来多次训练,训练模型的方差;实验采用多项式拟合数据,通过提高幂指数项个数改变模型的复杂度,进而提升模型对真实模型的拟合程度。实验设置如下:
- 1. 数据通过对\( sin(2\pi *x) \)随机采样100点,同时添加均值为0,方差为1的高斯白噪声。同时生成这样的数据20组。
-
2. 采用多项式拟合数据,依次采用3阶多项式、9阶多项式、15阶多项式对数据进行拟合。
实验结果依次如下:
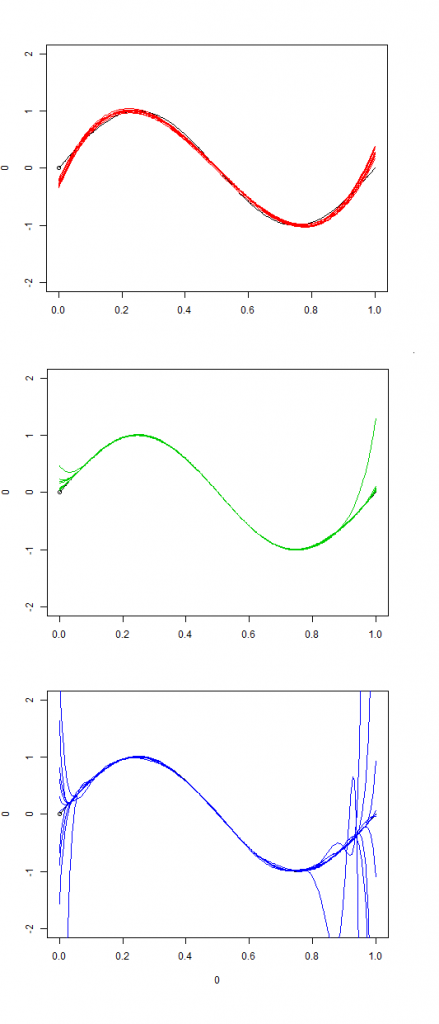
从以上结果可以看出,随着模型的复杂度的提高,所有模型的平均值对真实模型的拟合程度要好这体现训练模型的偏差;但是明显的看出,模型之间的方差也在增大。通过本实验可以复现并说明了偏差和方差随着模型复杂度的变化向相反的方向变化,但是变化的斜率并不一定是相等的。也就是说在实际模型训练的调参实质要解决的问题就是训练模型的偏差和方差的折中点。这和本文开始时提到的教练员从不同目标出发对测试结果的分析结果的选择类似。
通过以上分析可以得到MSE的两个主要组成部分,同时也可以对我们的模型训练有一定的指导意义,一些优化算法就是基于此分析开展,无非就是减小这两部分的某一部分。
偏差方差应用
最小化偏差
-
1. 增加参数,通过增加可以调节的参数数量,达到提升模型复杂度的目的。借助复杂的模型规则更好的拟合真实函数,进而减小方差。在本文实验中通过增加幂指数项个数的方法就是实现这个目的。
-
2. Boosting,就是通过多个弱分类器组合成强分类器的思想。而这里的弱分类器往往就是较为简单的模型,它是通过多个弱分类器对数据进行分析,经过投票,通过综合获得最终的分类结果。
- 3. …
正则化
-
1. 熟悉模式识别的人都熟悉模型训练中过于复杂的模型容易造成过拟合,而解决过拟合的首选方法就是正则化,通过正则化来限制模型有效参数的个数,达到降低模型复杂度的目的,进而实现降低方差的目标。
-
2. Bagging,该方法通过给定的算法,对原始数据集进行随机采样,并构建模型。最后通过多个模型的综合,作为最终的模型输出。提高了结果的稳定性,降低了训练模型的方差。
- 3. …
同时有些算法则是这两种思路的融合,最为常见的就是随机森林,它采用分类回归树最为基础算法,通过样本的有放返回随机采样,构建了不同的训练数据集,实现了bagging的思想;采用属性的无放回抽样,构建多个模型,并已投票结果作为输出,实现了boosting的思想。
原创文章,作者:admin,如若转载,请注明出处:https://www.isclab.org.cn/2016/01/21/bias-variance-trade-off/