EM(Expectation-maximization)算法是机器学习十大算法之一。它是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。EM算法的数学推理可以参考网址http://www.isclab.org.cn/archives/2014/12/2918.html,本章内容将以GMM模型展开。在文章最开始我们先来明确下参数估计的含义:参数估计(parameter estimation)是根据从总体中抽取的样本估计总体分布中包含的未知参数的方法。会先假定研究的问题具有某种数学模型。
高斯混合模型(Gasssian mixture model,简称GMM)是单高斯概率密度函数的延伸,由于GMM能够平滑地近似任意形状的密度分布,近几年来在语音辨别、图像识别等方向有不错的效果。这里将从单高斯概率密度函数开始讲起。
1.单高斯概率密度函数
假设有一组维度为d的样本点![]()
![]() , i=1…n,具有近似椭球状的分布,我们可以用高斯密度函数
, i=1…n,具有近似椭球状的分布,我们可以用高斯密度函数![]()
![]() 来描述产生这些点的概率密度函数:
来描述产生这些点的概率密度函数:
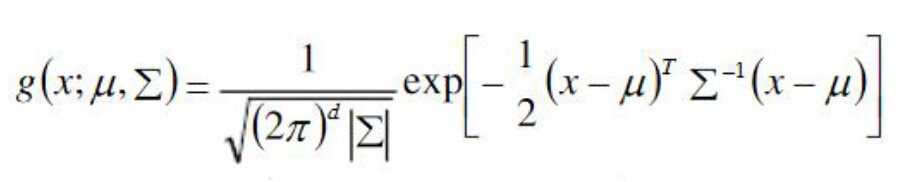

其中μ为该密度函数的均值(d维列向量),![]()
![]() 为该密度函数的协方差矩阵。这两个参数值的确定可以使得该概率密度函数有效描述样本点的分布状况。
为该密度函数的协方差矩阵。这两个参数值的确定可以使得该概率密度函数有效描述样本点的分布状况。
2.高斯混合概率密度函数
若样本点 ![]()
![]() 在d维空间中的分布不为椭球状,那么单高斯密度函数就不适合用来描述这些样本点的概率密度函数。于是采用一种方法来表示,多个高斯密度函数的加权平均。由此得到高斯混合模型的概率密度函数的分布模型:
在d维空间中的分布不为椭球状,那么单高斯密度函数就不适合用来描述这些样本点的概率密度函数。于是采用一种方法来表示,多个高斯密度函数的加权平均。由此得到高斯混合模型的概率密度函数的分布模型:
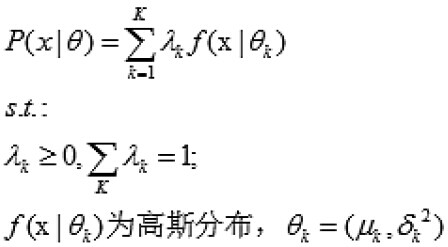
由公式我们可以看出,每一个GMM由k个Gaussian 分布组成,每一个Gaussian 称为一个“Component”,这些 Component线性加成在一起就组成了 GMM 的概率密度函数。其中 ![]()
![]() 是第k个Component的系数,
是第k个Component的系数,![]() 的值可以确定第k个Component的Gaussian 分布。所以我们需要确定的参数
的值可以确定第k个Component的Gaussian 分布。所以我们需要确定的参数![]() 和系数
和系数![]() 。到此,我们知道GMM是怎么组成的,那么当有一组需要用GMM描述的数据时,我们如何确定这个模型的参数?这些参数代表的含义?
。到此,我们知道GMM是怎么组成的,那么当有一组需要用GMM描述的数据时,我们如何确定这个模型的参数?这些参数代表的含义?
3.高斯混合模型参数估计的EM算法
重点来了,EM算法的用武之地。模型参数的求解是如何和EM算法相互联系的?对我们来说样本点X是不完全数据,因为我们不知道样本点 X来自哪个Component。所以这里的存在隐变量,我们用 ![]()
![]() 表示,其定义如下:
表示,其定义如下:

![]()
![]() 是0-1随机变量。
是0-1随机变量。
从这里开始,我们可以把EM算法的原理应用到GMM的参数估计上。首先,我们明确隐变量,写出完全数据的对数似然函数。此时完全数据为![]()
![]() ,i=1,2…,n 。之后,是EM算法的E步,确定
,i=1,2…,n 。之后,是EM算法的E步,确定![]() 函数,其公式为:
函数,其公式为:
![]()
![]()
这里需要计算 ![]()
![]() ,记为
,记为![]() ,其具体的公式将算法流程中写出。最后,我们确定EM算法的M步。迭代的M步是求函数
,其具体的公式将算法流程中写出。最后,我们确定EM算法的M步。迭代的M步是求函数![]() 的极大值,即求新一轮迭代的模型参数:
的极大值,即求新一轮迭代的模型参数:
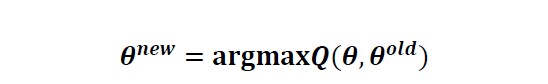
我们用![]()
![]() ,
,![]() ,
,![]() 表示
表示![]() 的各参数。对于
的各参数。对于 ![]() ,
,![]() 我们可以通过将
我们可以通过将![]() 分别对
分别对 ![]()
![]() ,
,![]() 求偏导数并令其为0,即可得到;
求偏导数并令其为0,即可得到;![]()
![]() 是在求和为1的条件下求偏导数并令其为0得到的。其具体的公式我们同样在算法流程中写出。
是在求和为1的条件下求偏导数并令其为0得到的。其具体的公式我们同样在算法流程中写出。
3.1 GMM参数估计的EM算法流程
Input: 观测数据(n个),高斯混合模型(预设参数,k个分模型)。
Output:高斯模型参数(![]()
![]() ,
,![]()
![]() ,
,![]() ,
,![]()
![]() )
)
1)取参数的初始值开始迭代
2)E步:依据当前模型参数,计算各 Component对样本点![]()
![]() 的响应度
的响应度
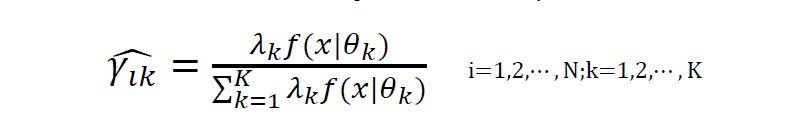
3)M步:计算新一轮迭代的模型参数
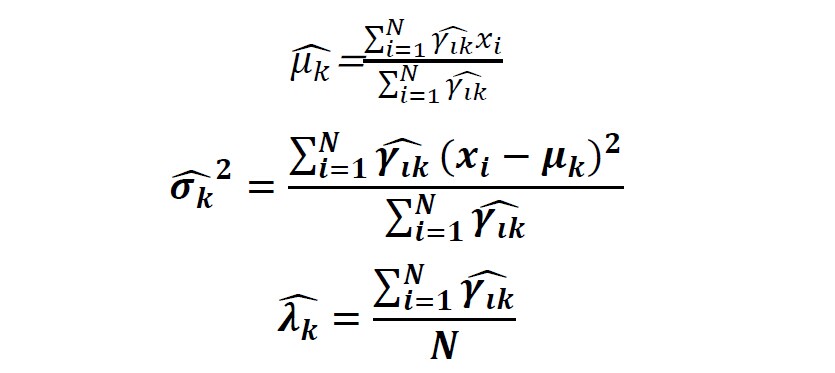
这里k=1,2, …K
4)重复以上两步,直到收敛。
3.2GMM参数估计的几点说明
由于GMM参数估计是EM算法的应用,所以在EM算中需要说明的几点内容在这里进行简单介绍:
步骤1,参数的初值可以任意选择,但需要注意算法对初值是敏感的;
步骤2,E步求Q函数.每次迭代实际在求Q函数及其极大;
步骤3,M步求Q函数的极大化,完成一次迭代.每次迭代使似然函数增大或达到局部极值;
步骤4,给出停止迭代条件,一般是满足:
![]()
![]()
其中![]()
![]() ,
,![]() 为较小的正数。
为较小的正数。
除此之外,我们所求的各参数具体有什么含义?下面对参数指标进行简单介绍:
![]()
![]() :当前模型参数下第i个观测数据来自第k个分模型的概率,这对应前面提到的响应度问题。此参数值作为重要指标用在对样本聚类分析上。
:当前模型参数下第i个观测数据来自第k个分模型的概率,这对应前面提到的响应度问题。此参数值作为重要指标用在对样本聚类分析上。
![]()
![]() :第k个Component的均值,其度量和样本度量一样。
:第k个Component的均值,其度量和样本度量一样。
![]()
![]() :第k个Component的方差,样本分布的走向,宽窄等需要它来描述。
:第k个Component的方差,样本分布的走向,宽窄等需要它来描述。
![]()
![]() :第k个Component的系数,用另一种方式理解就是样本点来自第k个Component的概率。
:第k个Component的系数,用另一种方式理解就是样本点来自第k个Component的概率。
4. GMM和K-means的区别
最后,在这里给大家说一下两者的区别。作为两种可以聚类的方法,大家经常会说明两者的区别。GMM和k-means其实是十分相似的,区别仅仅在于对GMM来说,引入了概率。用GMM的优点是投影后样本点不是得到一个确定的分类标记,而是得到每个样本点属于每个类的概率。所以在聚类分析划分簇(Component)的时候k-means将每个样本点指定一个簇的时候,该样本点对其他簇没有任何影响;而GMM中每个样本点都有对应各簇的概率值,故样本点对每一个簇都有影响。这就是soft assignment(GMM)和hard assignment(k-means)。此外,GMM不仅可以用在聚类上,也可以用在概率密度估计上。
以上内容参考来源广泛,难免有理解错误的地方,敬请指正。另外由于忘记出处,部分内容没有附加参考文献,敬请海涵。
参考资料:
[1]《Pattern Recognition And Machine Learning》
[2]李航.统计学习方法[M].北京:清华大学出版社,2012.162-165.
[3]http://blog.pluskid.org/?p=39
[4]http://www.cnblogs.com/zfyouxi/p/4004031.html
[5]http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
程慧
2014.12.10
原创文章,作者:admin,如若转载,请注明出处:https://www.isclab.org.cn/2014/12/11/em%e7%ae%97%e6%b3%95%e7%9a%84%e5%ba%94%e7%94%a8-gmm%e7%9a%84%e5%8f%82%e6%95%b0%e4%bc%b0%e8%ae%a1/